# 堆
目前 Linux 标准发行版中使用的堆分配器是 glibc 的堆分配器:ptmalloc2,主要通过 malloc/free 来分配和释放内存块。
不同的线程维护不同的堆称为:per thread arena。
主线程创建的堆称为:main arena。
# chunk 结构
我们一般称 malloc 出来的内存块为 chunk,这个内存块在 ptmalloc 用 malloc_chunk 结构体表示。
结构体定义:
/* | |
This struct declaration is misleading (but accurate and necessary). | |
It declares a "view" into memory allowing access to necessary | |
fields at known offsets from a given base. See explanation below. | |
*/ | |
struct malloc_chunk { | |
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */ | |
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */ | |
struct malloc_chunk* fd; /* double links -- used only if free. */ | |
struct malloc_chunk* bk; | |
/* Only used for large blocks: pointer to next larger size. */ | |
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */ | |
struct malloc_chunk* bk_nextsize; | |
}; |
prev_size:如果前一个 chunk 是空闲状态,prev_size 储存前一个 chunk 的大小;否则储存前一个 chunk 的数据。
size:本 chunk 的大小,必须是 2*SIZE_SZ 的整数倍,后三位分别是:
- NON_MAIN_ARENA(A):表示该 chunk 属于主分配区(1)或者非主分配区(0)。
IS_MAPPED(M):记录当前 chunk 是否是由 mmap 分配的,M 为 1 表示该 chunk 是从 mmap 映射区域分配的,否则是从 heap 区域分配的。
PREV_INUSE(P):记录前一个 chunk 块是否被分配。一般来说,堆中第一个被分配的内存块的 size 字段的 P 位都会被设置为 1,以便于防止访问前面的非法内存。当一个 chunk 的 size 的 P 位为 0 时,我们能通过 prev_size 字段来获取上一个 chunk 的大小以及地址。这也方便进行空闲 chunk 之间的合并。
fd、bk:chunk 处于分配时从 fd 字段开始就是用户数据了,chunk 空闲时会被添加到对应的空闲管理链表中。这时 fd、bk 就有其特殊意义:
- fd:指向下一个(非物理相邻)空闲的 chunk。
- bk:指向上一个(非物理相邻)空闲的 chunk。
fd_nextsize, bk_nextsize,也是只有 chunk 空闲的时候才使用,不过其用于较大的 chunk(large chunk)
- fd_nextsize:指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- bk_nextsize:指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适 chunk 时挨个遍历。
# 占用和空闲状态下的 chunk 结构示意图

当 chunk 空闲时,其 M 状态不存在,只有 A、P。
原本是数据区的地方存储四个指针,指针 fd 指向前一个空闲的 chunk,而 bk 指向后一个空闲的 chunk,plmalloc 通过这两个指针将大小相近的 chunk 连成一个双向链表。
对于 large bin 中的空闲 chunk,还有两个指针 fd_nextsize 和 bk_nextsize,这两个指针用于加快 large bin 中查找最近匹配的空闲 chunk 。不同的 chunk 链表又是通过 bins 或者 fastbins 来组织。
当 chunk 占用时,前两个字段被称为 chunk_header,后面的部分称为 user_data,每次通过 malloc 申请到的内存指针,其实是从 data 开始的。
因此,虽然存在一个 chunk 指针指向 chunk_header,但真正返回给用户的是指向 user_data 的指针。
一般情况下,物理相邻的两个空闲 chunk 会被合并为一个 chunk 。堆管理器会通过 prev_size 字段以及 size 字段合并两个物理相邻的空闲 chunk 块
# bins
bin 链表中指向的是 chunk_header。
当 chunk 被释放时,会通过一个 bin 链表统一管理,ptmalloc 会根据 chunk 的大小和使用情况,将 chunk 分为 4 种类型。
- fastbin:用于管理较小的 chunk。
- smallbin:用于管理中等大小的 chunk。
- largebin:用于管理较大的 chunk。
- unsortedbin:用于管理未整理的 chunk
# fastbin
我们在写程序时,经常会申请一些较小的堆块。在没有 fastbin 的情况下,free 掉堆块后,通常会将其与其他堆块合并,导致我们下一次申请同样大小的堆块时,需要重新切割堆块。fastbin 的存在省去了合并和切割的步骤,增加了堆块的使用效率。
进入 fastbin 的堆块由一个单链表进行管理,后进先出,相同大小的堆块在同一条链上,不同大小的堆块在不同的单链表上,并且,fastbin 中的堆块的 p 位会被保留,以此来防止堆块合并。
# unsortedbin
一般情况下,当一个堆块被释放时,如果它的大小不属于 fastbin,并且它不和 top chunk 相邻,就会放到 unsortedbin 中。除此之外,还有两个来源:
当一个较大的堆块被分割成两半后,如果剩下的部分大于 MINSIZE 就会被放到 unsorted bin 中。
当进行 malloc_consolidate 时,如果不和 top chunk 相邻,可能会把合并后的堆块放到 unsortedbin。
进入 unsortedbin 的堆块由一个双向循环链表进行管理,先进先出。链表中的空闲堆块处于乱序状态,当我们申请堆块时,如果在其他 bin 中没有找到合适的堆块,就会遍历 unsortedbin 寻找,这时会把 unsortedbin 中的堆块根据大小放到对应的 bin 中。
# smallbin
unsortedbin 中大小为 2*SIZE_SZ*index index∈[2,63] 的堆块会被分配到 smallbin 中。
进入 smallbin 的堆块由 62 个双向循环链表进行管理,先进先出。相同大小的堆块在同一条链上,不同大小的堆块在不同的链表上。
# largebin
unsortedbin 中大于等于 512(x32)|1024(x64) 的堆块会被分配到 largebin 中。
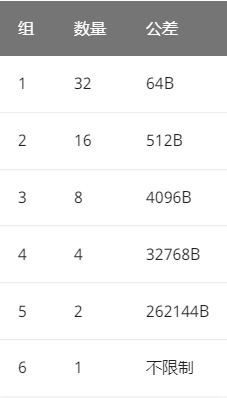
进入 largebin 的堆块由 63 个双向链表进行管理,63 个链表被分为 6 组,每组链表可以储存的堆块大小范围不同,如下图所示:
以 64 位为例:
第一组第一个 largebin 可以储存大小为 [1024,1024+64) 的堆块。
第一组第二个 largebin 可以储存大小为 [1024+64,1024+64+64) 的堆块。
第一组总共有 32 个 largebin。
依此类推……
第二组第一个 largebin 可以储存大小为 [3072,3072+512) 的堆块。
第二组总共有 16 个 largebin。
依此类推……
第六组只有一个 largebin,它储存的堆块大小没有限制。
在同一个 largebin 中,堆块的大小是不一定相同的,因此需要使用 fd_nextsize 和 bk_nextsize 两个指针来对不同大小的堆块进行从大到小的排序。
# tcache
tcache 是在 libc 2.26 后引入的一种新的缓存机制。它为每个线程增加了一个 bin 缓存,从而提高了小内存的分配速度。在释放堆块时,会先检查堆块的大小,确认合法后,在放入 fastbin 之前,会先尝试将它放入 tcache 中。在申请堆块时,会优先使用 tcache 中合适的堆块。
进入 tcache 的堆块由一个单链表进行管理,后进先出,每个 tcache 中至多有 7 个堆块,并且,tcache 同样保留 p 位,也就是说 tcache 中的堆块不会被合并。